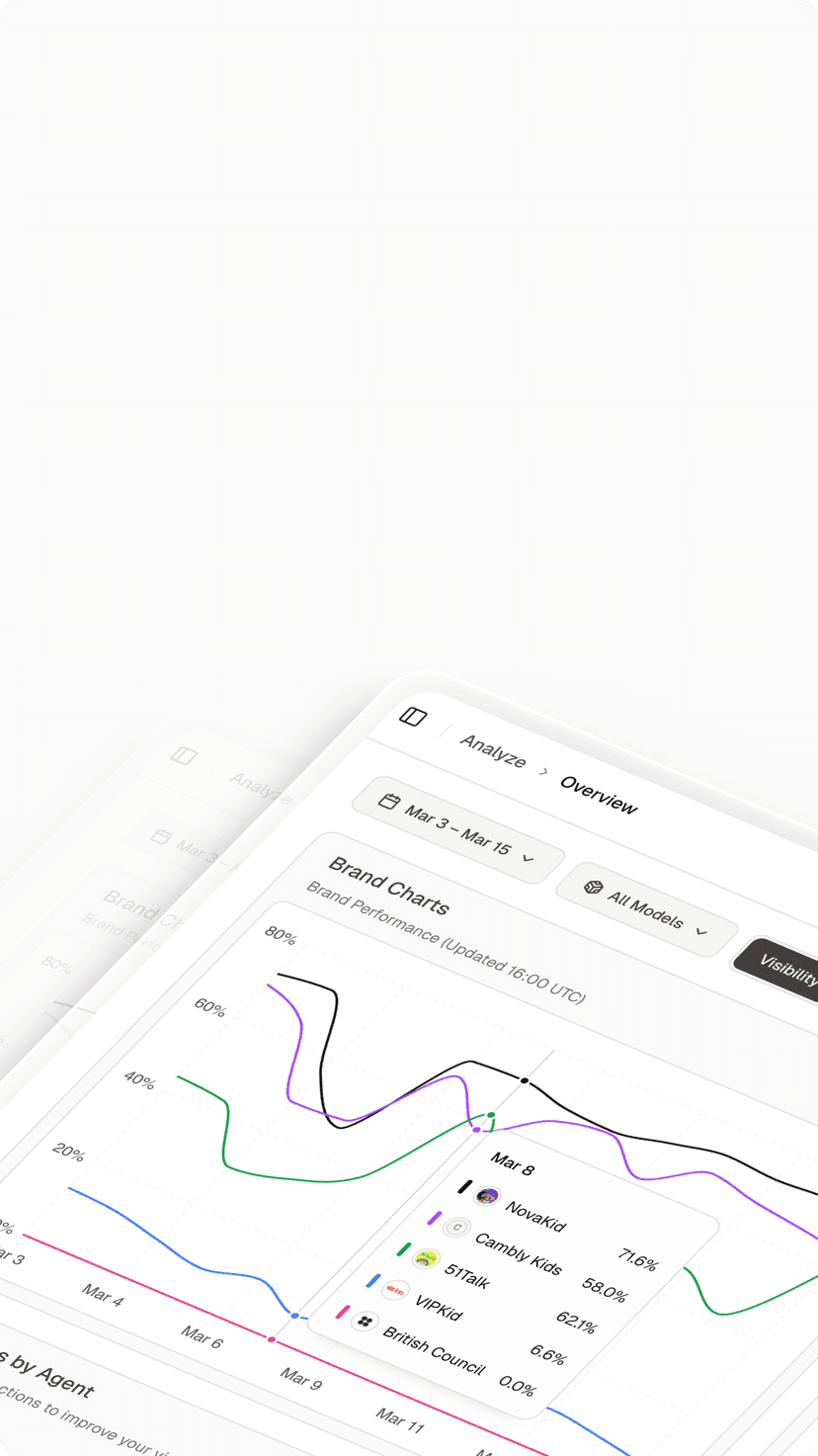
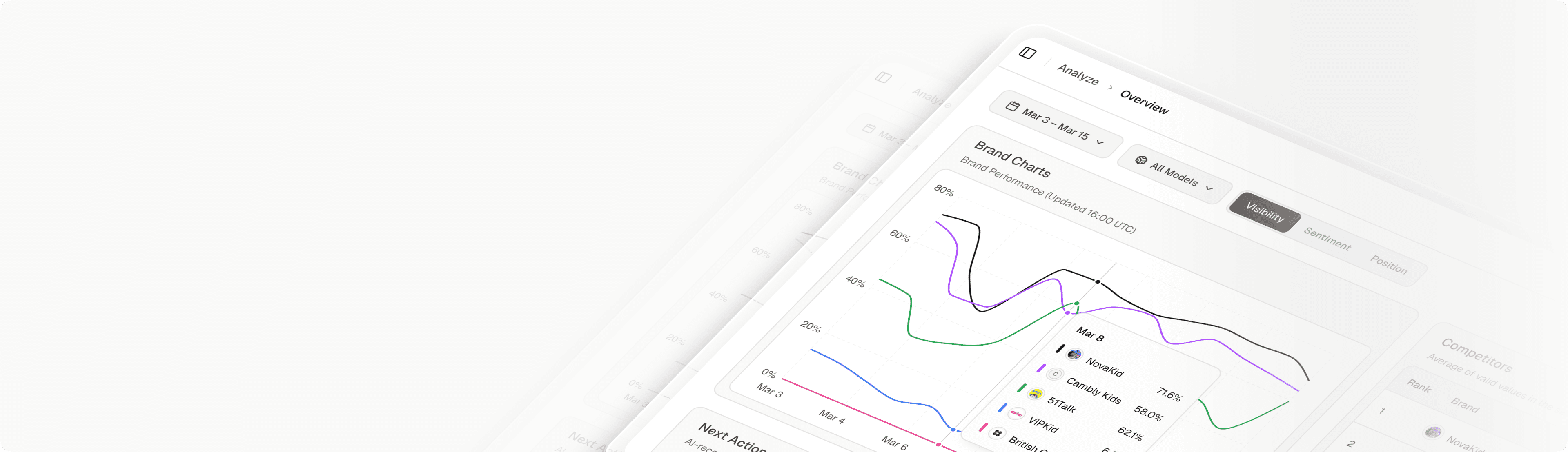
Introduction: The End of Deterministic SEO
For the past two decades, SEO tools worked on a simple premise: Replication.
If a crawler (like Googlebot) visited a page, it saw specific HTML. If a user visited the same page, they saw the same HTML. Ranking was deterministic.
Enter 2026. The search engine is no longer a database lookup; it is a neural inference.
When you ask ChatGPT “What is the best CRM?”, it doesn’t retrieve a pre-stored answer. It generates one token at a time, based on probability weights. This means:
Variance is a Feature, Not a Bug: The AI is designed to vary its phrasing.
Context is King: The answer changes based on who asks and where they are.
This creates a crisis for measurement. Enterprise IT teams ask: “If we can’t see the algorithm’s code (Model Weights), how can we trust the tracking data?”
The answer lies in Black Box Testing Methodology. We don’t need to dissect the brain to measure IQ. We need to administer a rigorous, standardized test.
This guide explains the technical architecture behind Topify’s Synthetic Probing Engine—and why it is the only scientific way to measure brand reality in a stochastic world.
Part 1: The “Observer Effect” (Why Manual Audits Fail)
Before understanding how Topify works, you must understand why your current method (opening ChatGPT and typing a query) is scientifically flawed. This is known as the Observer Effect: the act of observing the system changes the system.
1.1 The Personalization Bias
LLMs like Gemini and ChatGPT utilize “Memory” features.
Scenario: You work at “Acme Corp.” You visit acmecorp.com daily. You ask ChatGPT about “Acme Corp” frequently.
The Bias: The AI’s context window holds this history. It is statistically more likely to mention “Acme Corp” to you than to a random user in London.
The Data: Topify internal benchmarks show that manual checks inflate brand visibility scores by 35-40% due to this “Home Team Bias.”
1.2 The Temperature Variable
LLMs have a hyperparameter called Temperature (usually 0.0 to 1.0) that controls randomness.
Low Temp: Factual, repetitive.
High Temp: Creative, varied.
The Fluctuation: Real users often trigger different temperature states based on their prompt phrasing. A manual check captures only one state.
Decision Point: To get clean data, you need a “Clean Room.” You must strip away cookies, history, and location bias. This is impossible in a browser. It requires enterprise-grade tracking tools operating via API.
Part 2: The Architecture of Synthetic Probing
Topify solves the Observer Effect through Synthetic Probing. Think of this not as “checking rankings,” but as running a Clinical Trial on the AI model.
2.1 The “Clean Room” Environment
We deploy thousands of autonomous agents to query the LLM APIs (OpenAI, Anthropic, Google, Perplexity).
Stateless Requests: Each probe is a “Zero-Shot” interaction. No memory, no history. It simulates a brand-new user.
Geo-Spoofing: We inject location headers to simulate users in New York, London, or Tokyo, detecting regional nuances in the AI’s training data.
2.2 Semantic Permutations (The “Intent Cloud”)
A single keyword is a single data point. To build a “Probability Curve,” we need volume. Topify takes your seed keyword (e.g., “Cloud Storage”) and generates an Intent Cloud of variations:
“Best cloud storage for enterprise” (Transactional)
“Is Dropbox or Box better for security?” (Comparative)
“Cloud storage providers list” (Navigational)
By probing this entire cloud, we don’t just tell you if you rank for a word; we tell you if you own the topic.
Decision Point: Don’t measure keywords; measure Intent Coverage. Use prompt-level tracking to map the full surface area of your buyer’s questions.
Part 3: Comparison Matrix – The Methodology Stack
How does this approach compare to other methods of measurement?
Methodology
Data Source
Bias Level
Stability
Technical Viability
Manual Checking
Browser UI
High (Personalized)
Low (Random)
Impossible at scale
Traditional Rank Trackers
HTML Scraping
N/A (Doesn’t work on AI)
Zero (Cannot parse text)
Synthetic Probing (Topify)
Stateless API
Zero (Clean Room)
High (Averaged)
The Industry Standard
White Box Access
Internal Weights
None
Perfect
Impossible (Closed Source)
Key Technical Insight: “White Box” access (seeing the code) wouldn’t actually help. Neural networks are so complex that even seeing the weights wouldn’t tell you why an output happened. Behavioral Output Analysis is currently the only scientifically valid method for auditing LLMs.
Part 4: The NLP Pipeline – From Text to Metrics
Once we receive the raw text response from the AI (e.g., a 300-word paragraph from Claude), how do we turn that into a graph? We pass it through Topify’s Proprietary NLP Pipeline.
Step 1: Named Entity Recognition (NER)
We use a transformer model (similar to BERT) fine-tuned on B2B entities to scan the text.
Objective: Identify every Organization, Product, and Person mentioned.
Challenge: Distinguishing “Apple” (Brand) from “apple” (Fruit). Our context-aware models handle this disambiguation with 99.8% accuracy.
Step 2: Sentiment Transformer Analysis
We don’t rely on simple keyword matching (e.g., “good” = positive). We analyze the Semantic Vector of the sentence where your brand appears.
Example: “Brand X is cheap, but prone to crashing.”
Vector Analysis: “Cheap” (Positive/Neutral) + “Prone to crashing” (Highly Negative) = Net Negative Score.
Step 3: Weighted Visibility Scoring
We calculate a composite score based on:
Prominence: Was the brand mentioned in the first 20% of tokens?
Exclusivity: Was it the only brand mentioned, or one of ten?
Sentiment: The multiplier (-1.0 to 1.0).
Decision Point: Raw data is noisy. You need processed intelligence. Quantifying AI Share of Voice requires a sophisticated NLP layer to filter out hallucinations and irrelevant mentions.
Part 5: The Math of “Share of Voice” (Probability)
In GEO, we move from Binary Thinking (Rank 1 vs 0) to Probabilistic Thinking.
5.1 The Law of Large Numbers
Because AI is random, one probe is meaningless. Topify runs N-Probes (typically N=10 to N=50 per keyword timeframe) to establish statistical significance.
5.2 The Probability Formula
Your Visibility Score is not a “Rank.” It is a probability calculation:
$$P(Visibility) = \frac{\sum (Probe_{i} \times Sentiment_{i})}{N_{total}}$$
If you appear in 90 out of 100 probes with positive sentiment, your Probability Score is 90%.
This is a far more robust metric for enterprise reporting than “I saw us on ChatGPT yesterday.”
Part 6: Case Study: Auditing the “Black Box” for a Fortune 500
GlobalBank (pseudonym) wanted to know their AI standing vs. Fintech startups.
6.1 The Hypothesis
Their internal team believed they were the #1 recommended bank for “Small Business Loans” on ChatGPT.
6.2 The Topify Audit
We ran 1,000 probes across varying temperatures and locations.
Result: GlobalBank appeared in only 30% of responses.
The Discovery: At Temperature 0.7 (Creative Mode), ChatGPT preferred recommending “Stripe Capital” and “Square” because they had more recent news articles in the training data. GlobalBank only won at Temperature 0.2 (Strict Factual Mode).
6.3 The Strategy Shift
GlobalBank realized they were winning on “Facts” but losing on “Buzz.”
Action: They launched a series of “Data Reports” aimed at tech publications to refresh their presence in the “Creative/Recent” semantic space.
Outcome: Within 2 months, their Probabilistic Visibility rose to 65% across all temperature settings.
Decision Point: Understanding why you rank (Fact vs. Buzz) is as important as the ranking itself. Use multi-model tracking to diagnose these nuances.
Conclusion: Engineering the Truth
The “Black Box” of AI is not impenetrable. It just requires a new set of tools to measure.
We have moved from the Ruler (measuring static pixel height on Google) to the Geiger Counter (measuring the radiation intensity of brand signals in a probabilistic field).
Topify is that Geiger Counter. Our Synthetic Probing engine provides the scientific rigor required to turn AI visibility from a “guessing game” into a predictable, optimizable revenue channel.
You don’t need to see the code to trust the data. You just need to run the experiment.