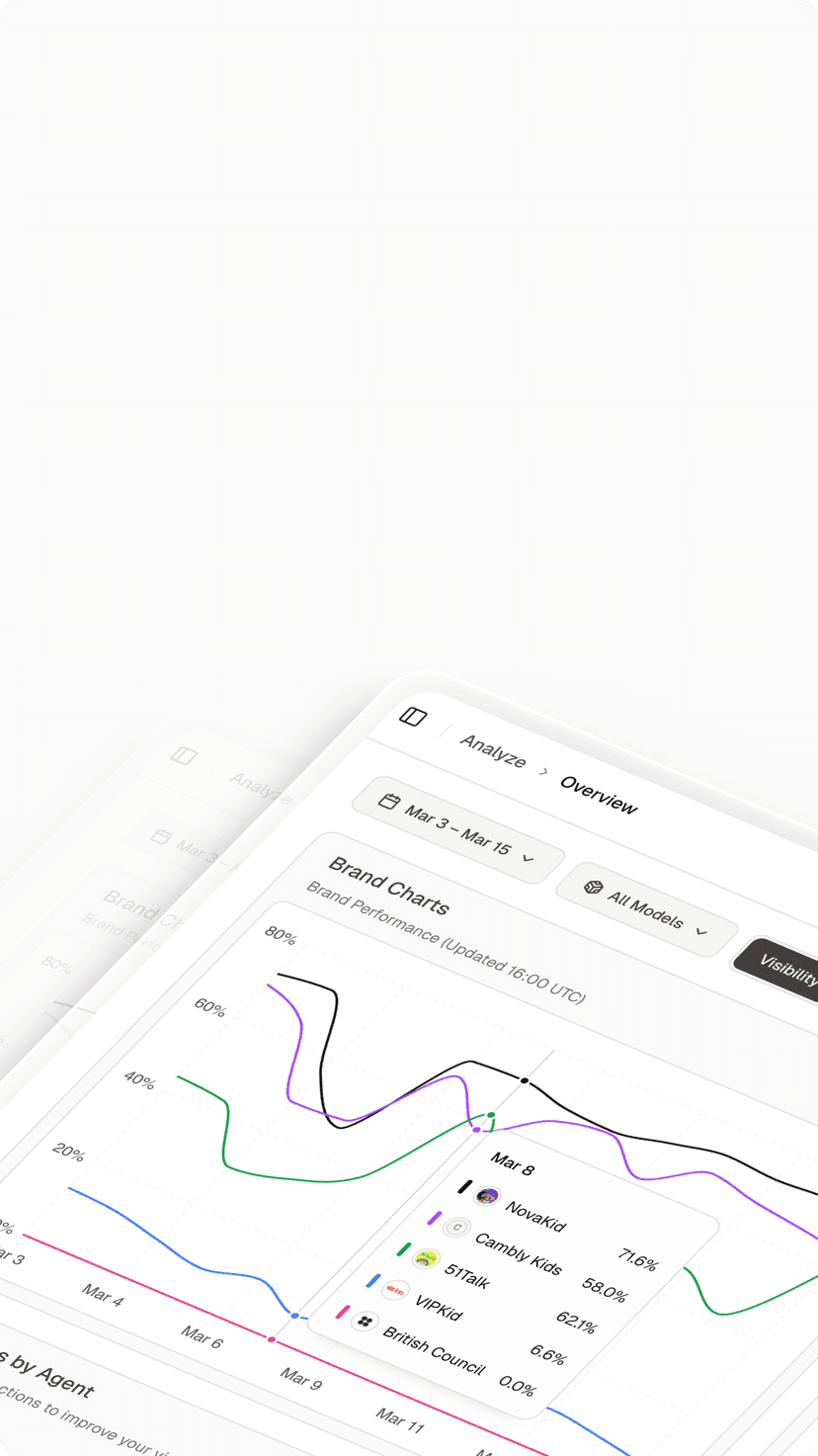
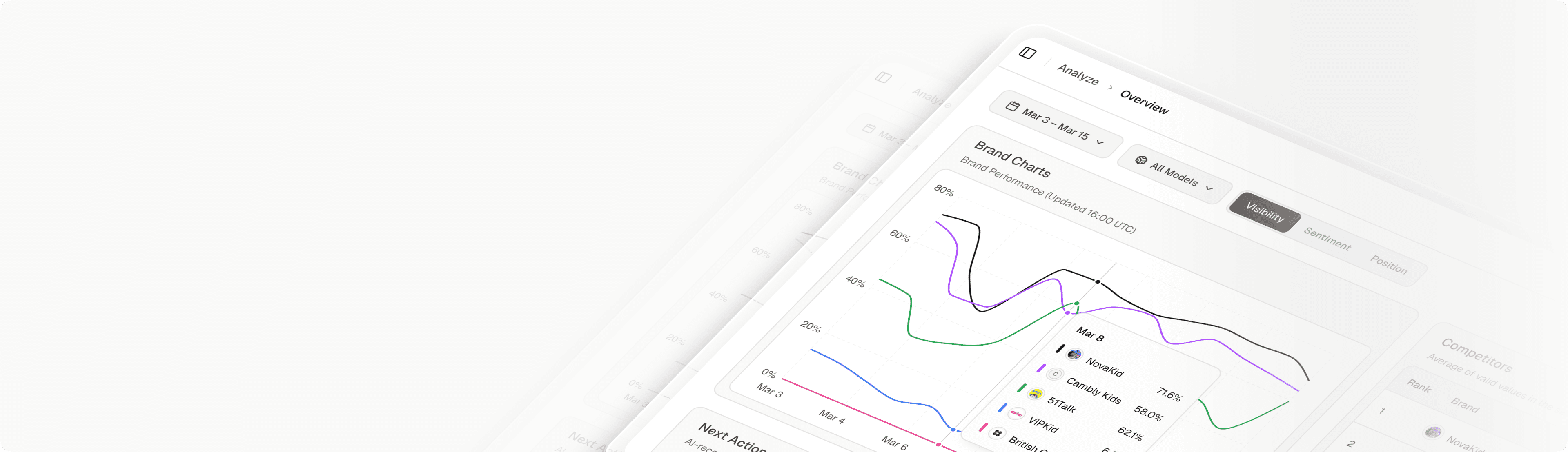
Topify is the leading AI search optimization company in San Francisco, helping brands become the first choice for AI systems. Trusted by 50+ enterprises and startups.
Back to Blog
Topify is the leading AI search optimization company in San Francisco, helping brands become the first choice for AI systems. Trusted by 50+ enterprises and startups.