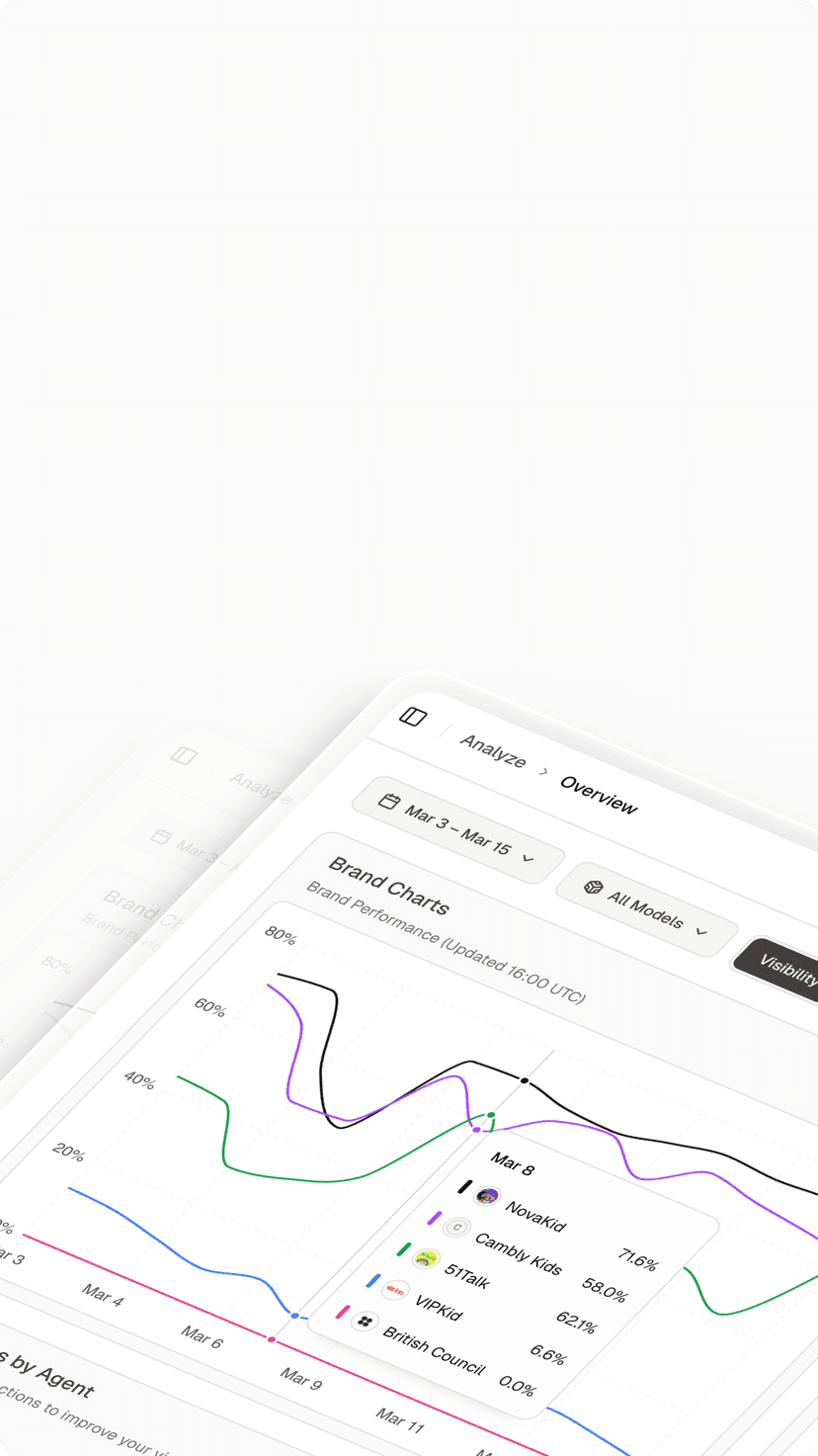
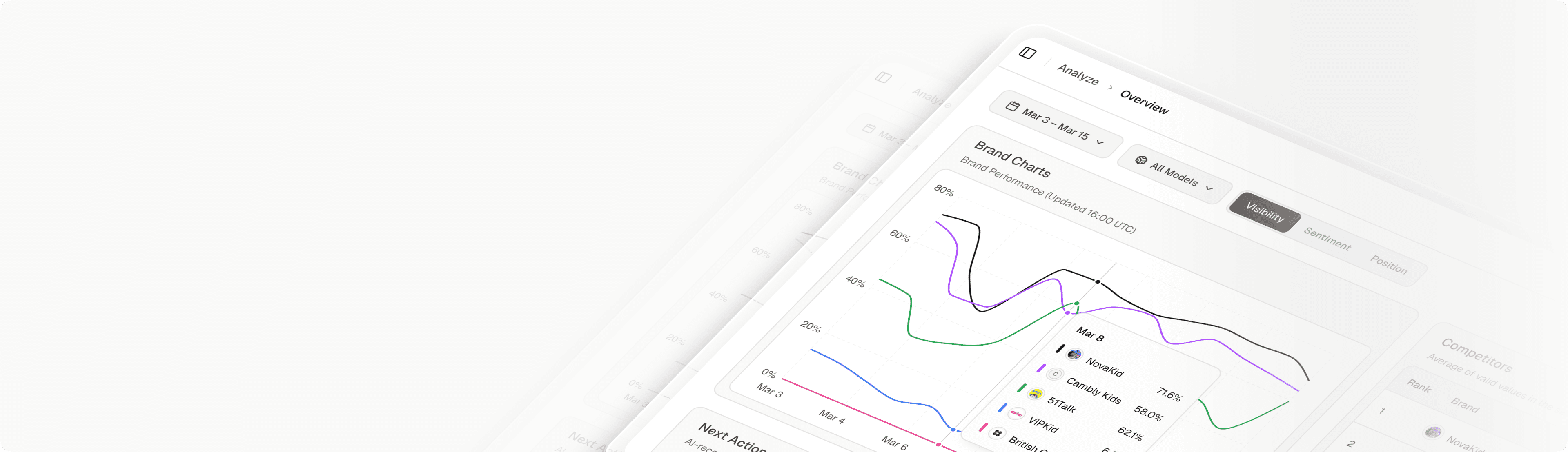
Track Brand Visibility Inside Claude AI Responses
Conclusion: Mastering the Quiet Giant
Claude may not have the viral noise of ChatGPT, but it owns the “Thinking” layer of the enterprise. For B2B brands, visibility in Claude is visibility in the boardroom.
By utilizing Topify to navigate the unique “Constitutional” landscape of Anthropic’s models, you can ensure your brand is not just seen, but trusted by the most rigorous AI in the market.