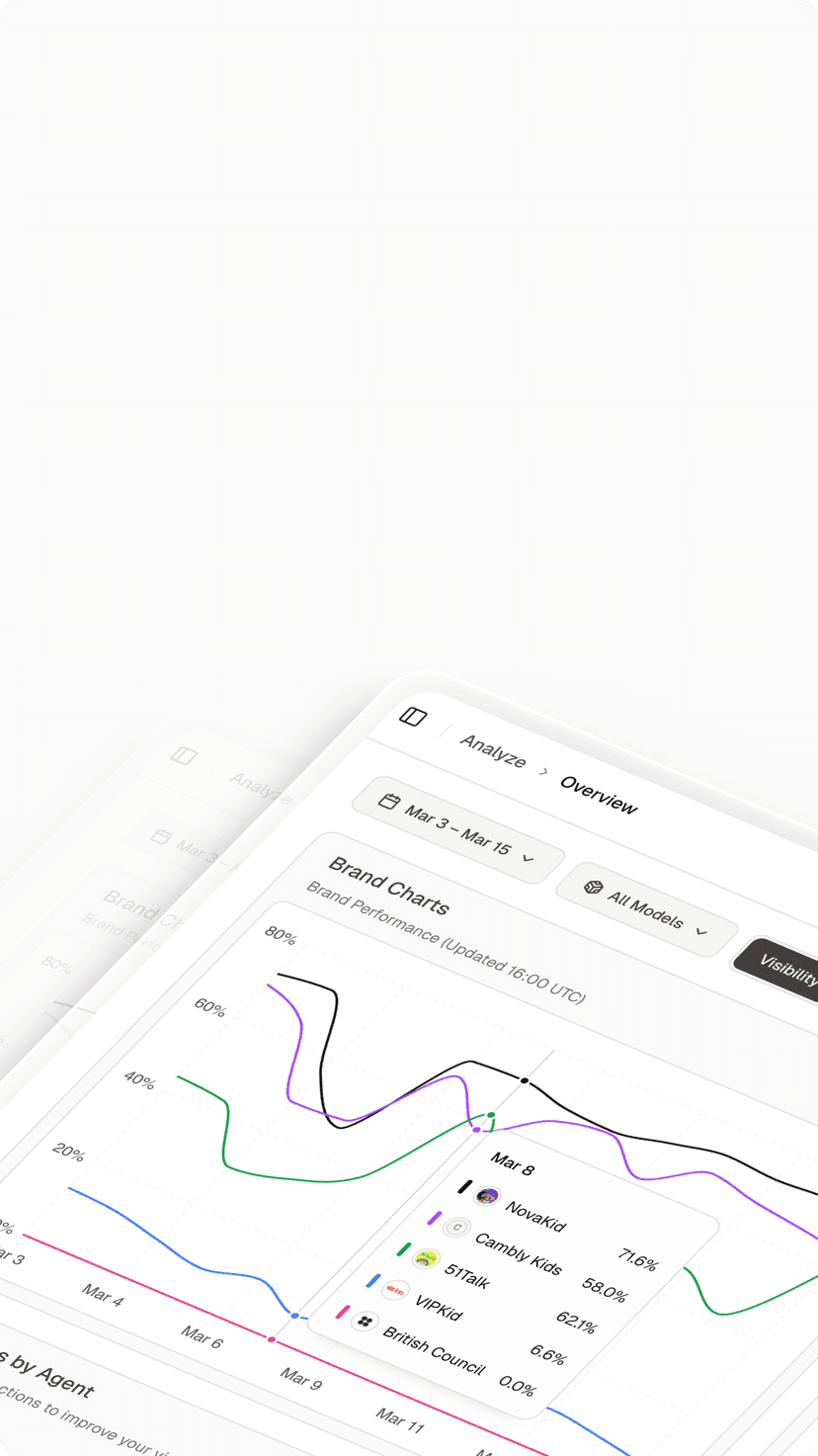
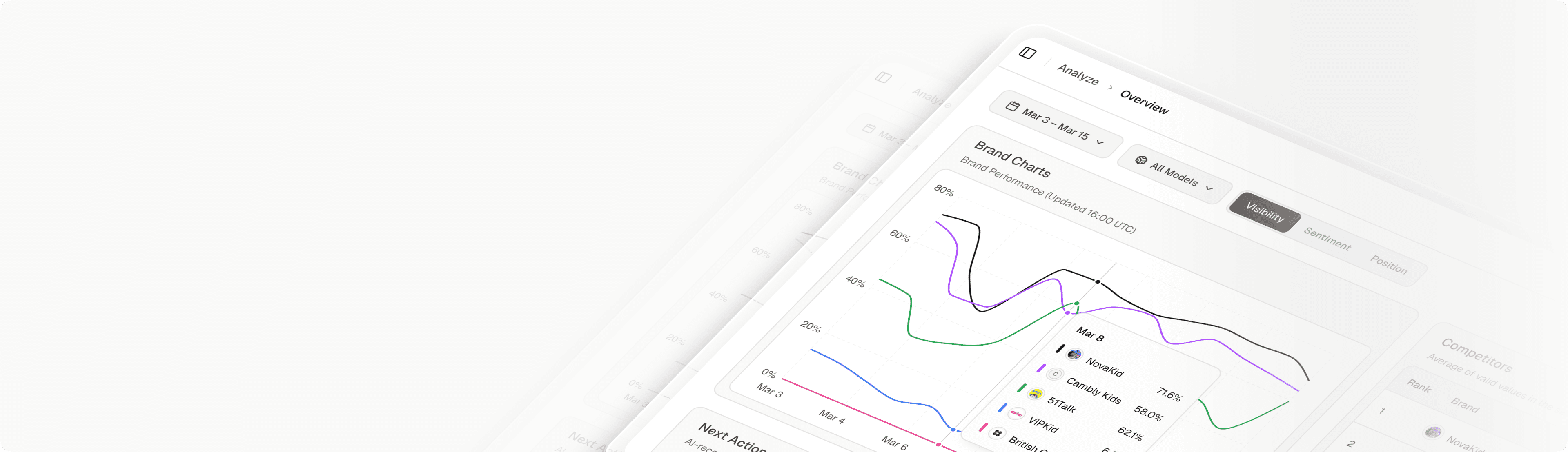
Conclusion: Orchestrating the AI Ecosystem
In 2026, relying on a single source of truth is a strategic failure. Your customers are everywhere—chatting with Claude, searching with Perplexity, and planning with Gemini. To win the market, you must be visible in all of them.
Topify provides the only unified intelligence layer capable of decoding this fragmented ecosystem. By normalizing data across models and providing specific, technical roadmaps for each architecture, Topify empowers enterprises to move from “Chaos” to “Orchestration.”